




大模型训练全过程关键步骤与核心要点详解

深入解析大语言模型训练的每一步:从预训练到RLHF 训练一个大语言模型,听起来像是科幻电影里的操作,但实际上,背后每个环节都被研究得很透彻。先把核心框架说清楚:整个过程可以拆成四个模块——预训练、指令微调、奖励模型训练、以及基于人类反馈的强化学习。每个模块都有自己的使命,缺一不可。 这篇文章会完整梳
深入解析大语言模型训练的每一步:从预训练到RLHF
训练一个大语言模型,听起来像是科幻电影里的操作,但实际上,背后每个环节都被研究得很透彻。先把核心框架说清楚:整个过程可以拆成四个模块——预训练、指令微调、奖励模型训练、以及基于人类反馈的强化学习。每个模块都有自己的使命,缺一不可。
这篇文章会完整梳理从零开始训练大语言模型的全过程,包括每个阶段的核心思想、实现方式以及关键细节。如果你对“ChatGPT是怎么炼成的”感兴趣,这篇很合适。

一、预训练阶段(Pretraining)
预训练是现代NLP的基石,尤其对于基于Transformer架构的模型——无论是GPT系列还是BERT,都得先过这一关。目标很明确:让模型从海量的无标注文本中,学会语言的基本规律——语法结构、语义关系、长距离依赖……这些能力就像高中生通过三年的系统学习积累知识,为后续的专项冲刺打好基础。
整个过程可以类比为“读万卷书”:模型不需要人为标注数据,而是通过自监督学习来自己摸索规律。
1.1 核心思想
预训练主要分为自监督学习和无监督学习两大类,实践中用得最多的是自监督学习。关键是三个要素:
- 目标设定:学习语言的内部结构、词汇关系以及上下文依赖。
- 数据准备:使用海量无标注文本,来源包括互联网、书籍、新闻等。
- 训练目标:通过预测文本的某个部分(比如下一个词或遮住的词)来学习语言规律。
1.2 Transformer架构概述
Transformer是现代大模型的骨架。它由两个核心部件组成:
- 自注意力机制(Self-attention):让每个token在处理时能“关注”到序列中其他位置的token,从而捕获长距离依赖。
- 多头注意力(Multi-head Attention):将多个注意力头组合,模型能在不同子空间中学习多种依赖关系。
- 前馈神经网络:每一层Transformer都包含一个前馈网络,进一步加工注意力层传来的信息。
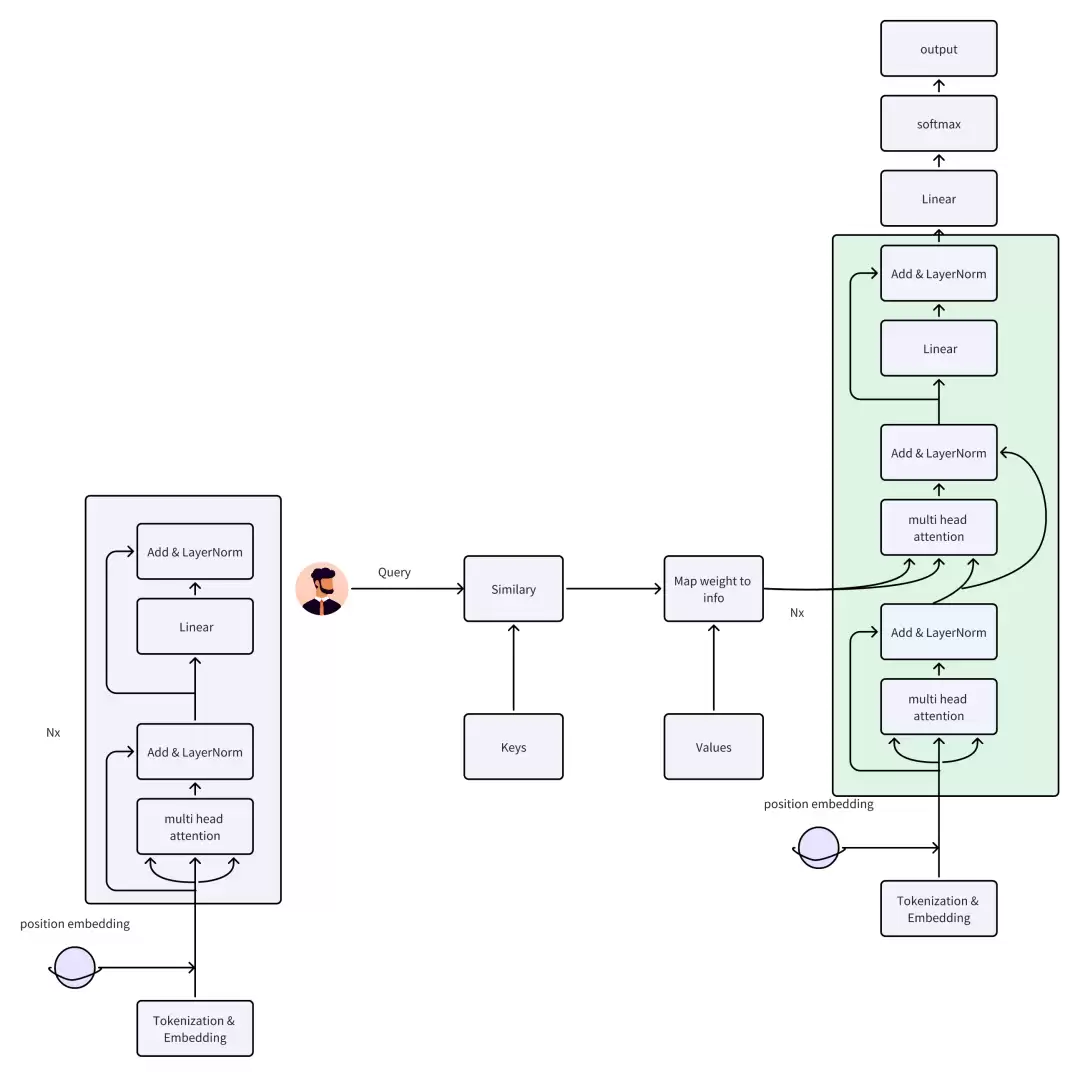
【进一步阅读】如果你想深入Transformer的细节,可以参考《NLP 基础知识库 | 3 Transformer(二)》。
1.3 具体流程
大模型的预训练通常按下面几步走:
(1)数据准备
用到的是大规模无标注文本——比如Wikipedia、BooksCorpus、Common Crawl等。这些原始文本需要处理:
- 分词(Tokenization):将文本拆成tokens。现代模型多用子词级别的分词方法(例如BPE或SentencePiece),好处是可以灵活处理未登录词(OOV)。
- 嵌入(Embedding):每个token通过嵌入层映射为高维向量,送入模型继续处理。
(2)训练目标设定
不同模型架构会选用不同的预训练任务:
自回归语言建模(Autoregressive Language Modeling) ——主要用于生成式预训练(如GPT)。模型的任务是:给定前面的所有token,预测下一个token。每一步都根据前文更新预测。
具体来说,模型学习条件概率分布:给定序列前文,预测下一个词的概率。
自编码语言建模(Autoencoding Language Modeling) ——主要用于BERT类模型。模型的任务是:输入序列中一部分token被遮住(用[MASK]代替),模型根据上下文预测这些被遮住的token。
例子:
The quick brown fox jumps over the [MASK] dog.模型要预测[MASK]位置的词是“lazy”。这种方式让模型学会双向上下文信息,适合理解语义关系的任务。
(3)模型训练
模型通过前向传播计算预测值,然后计算损失(预测值与真实值的差距),再用梯度下降和反向传播优化参数。最常用的优化器是Adam,它在处理稀疏梯度和大规模数据时非常高效。
损失函数因任务而异:
- 自回归模型:使用交叉熵损失,目标是让预测的token分布尽量贴近真实分布。
- 自编码模型:同样使用交叉熵损失,但只针对被遮住的token计算。
通过大规模预训练,模型捕捉到了语言中丰富的结构和语义信息,为下游任务的迁移学习打下坚实基础。比如自回归模型在预测下一个词的过程中,学会了词与词之间的依赖关系,也让生成内容更流畅、更一致。
二、监督微调阶段(Supervised Finetuning)
预训练结束后,模型已经是个“通才”,但还不能很好地处理具体任务。这时候就需要监督微调(Supervised Fine-Tuning, SFT)来让模型在特定任务上更精准高效——好比学生为了高考做专项模拟训练。
这个阶段最常见的方式是指令微调(Instruction Finetuning),下文说的SFT就指它。
2.1 数据准备
数据有两个主要来源:一种是人工标注,另一种是通过类似ChatGPT的模型自动生成。后者大大降低了成本。比如斯坦福的Alpaca项目就用ChatGPT自动生成了5200条指令-答案对,效率很惊人。
(1)文本数据格式
{
"Instruction":"",
"Input":"", //Input字段可选,有时Instruction会包含Input
"Output":""
}
// 例子:
{
"Instruction":"请帮我翻译一句话",
"Input":"hello",
"Output":"你好"
},
{
"Instruction":"请帮我翻译一句话:hello",
"Input":"",
"Output":"你好"
}(2)数据编码格式
首先用和预训练时相同的分词器(如BPE、SentencePiece)将文本拆成token。然后将输入和输出拼成一个序列,常用格式:
[Instruction] + [分隔符] +([Input])+ [分隔符] + [Output]例子:
用户:请解释量子力学的基本概念。\n助手:量子力学是描述微观粒子行为的物理学分支……对应的Token序列和标签序列会按规则对齐。
需要注意几点:
- 输入的最大长度受模型上下文窗口限制(例如GPT-3是2048 tokens)。
- 超出时需截断或滑窗处理。
- 在批量训练时,所有样本必须保持相同形状,常用padding和截断来一致化。
2.2 训练目标与损失计算
SFT的目标是让模型生成的输出尽量接近标注的正确答案。与预训练预测下一个词不同,SFT需要预测整个输出序列。
数据包含输入(context)和输出(label),模型要学习生成整个label序列。损失计算延续了预训练阶段的逐token交叉熵,但加入了输入-输出对的监督信息,从而让模型生成更符合任务要求。
损失的具体流程:
- 前向传播:输入序列和输出序列拼接后送入模型,通过Transformer层计算每个位置的token概率分布。
- 计算概率分布:最后一层输出logits矩阵,形状为[L, V](L为序列长度,V为词表大小),对其应用softmax得到概率。
- 计算交叉熵损失:对输出序列中的每个token,计算预测概率和真实label的交叉熵,取平均作为总体损失。
三、奖励模型(Reward Model)
奖励模型(RM)是强化学习与人类反馈(RLHF)的关键一环。它的作用是给模型输出的文本质量打分,指导模型后续生成更符合人类偏好的内容。这就像高三老师专门研究往年高考题,然后辅导学生提高成绩。
3.1 为什么需要奖励模型?
指令微调(SFT)虽然让模型具备了一定能力,但输出仍可能不符合人类偏好——比如出现“幻觉”(内容不真实或不准确)或“有害性”(输出不当内容)。SFT只用了有限的人工标注数据,未必能彻底纠正预训练阶段潜藏的错误知识。要解决这些问题,就得引入奖励模型,利用强化学习进一步优化。
3.2 强化学习与奖励模型
强化学习的核心是奖惩机制。在RLHF中,奖励模型为每个生成的响应提供一个奖励分数,让模型学会哪些输出好、哪些不好。
奖励模型的训练数据来自人工标注的排序数据:标注员对多个生成的回答进行排名,奖励模型基于这些排名学习。与传统有监督学习不同,这种方式不要求对每个输出给出明确分数,而是通过相对排序来比较,这能有效减少主观差异,提高标注一致性。
3.3 训练奖励模型
(1)训练数据(人工排序数据)
标注人员对模型生成的多个答案排序,而不是打分。这种相对排序比直接打分更高效、更一致,因为评分容易受标注者主观偏好影响,而排序能统一标准。
数据格式有两种:
//基于比较的数据格式
{
"input": "用户输入的文本",
"choices": [
{"text": "候选输出 1", "rank": 1},
{"text": "候选输出 2", "rank": 2}
]
}
//基于评分的数据格式
{
"input": "用户输入的文本",
"output": "生成模型的输出文本",
"score": 4.5
}奖励模型的输入是拼接后的序列:input + [SEP] + choice。例如:
//原始数据
{
"input": "What is the capital of France?",
"choices": [
{"text": "The capital of France is Paris.", "rank": 1},
{"text": "The capital of France is Berlin.", "rank": 3},
{"text": "Paris is the capital of France.", "rank": 2}
]
}
//应输入到模型的数据
[Input] What is the capital of France? [SEP] The capital of France is Paris.
[Input] What is the capital of France? [SEP] The capital of France is Berlin.
[Input] What is the capital of France? [SEP] Paris is the capital of France.(2)上下文建模
奖励模型基于Transformer(如BERT、RoBERTa)对整个拼接文本编码,生成每个候选文本的上下文感知表示。
(3)计算得分或排序
- 回归任务:预测一个质量分数。
- 排序任务:对所有候选文本打分并比较,确保高质量文本得分更高。
(4)损失函数
回归任务使用均方误差(MSE)损失,排序任务常用对比损失(Contrastive Loss)或排名损失(如Hinge Loss)。
3.4 奖励模型的挑战
- 人类偏好的多样性:不同标注员看法不同,需要模型通过排序学习来容忍主观性。
- 模型不稳定:奖励模型通常较小,训练中可能不稳定,需配合正则化和优化技巧。
- 数据质量与多样性:训练数据必须覆盖多样化的问题和答案,否则模型学不到有效的评分规则。
四、基于人类反馈的强化学习(RLHF)
RLHF是将强化学习与人类反馈结合的方法,目标是根据人类反馈优化模型行为,使其输出更自然、更符合人类意图。这就像高考生根据模拟考的反馈调整答题策略。
4.1 RLHF框架的核心组件
几个关键元素协同工作:
- 强化学习算法(RL Algorithm):常用近端策略优化(PPO),一种on-policy算法,模型根据当前策略直接学习并更新。
- 行动(Action):模型根据提示生成的输出文本,包括所有可能的token及其排列组合。
- 环境(Environment):模型与外界交互的场景,提供状态、动作和奖励。
- 状态空间(State Space):输入给模型的提示或上下文。
- 动作空间(Action Space):模型所有可能的输出文本。
- 奖励函数(Reward Function):由奖励模型预测,为输出分配奖励或惩罚。
- 观察(Observation):模型接收的输入提示。
- 奖励机制(Reward):核心环节,基于奖励模型预测分配奖励。
4.2 RLHF实战应用:InstructGPT的训练过程
以InstructGPT(ChatGPT前身)为例,训练分三个阶段:
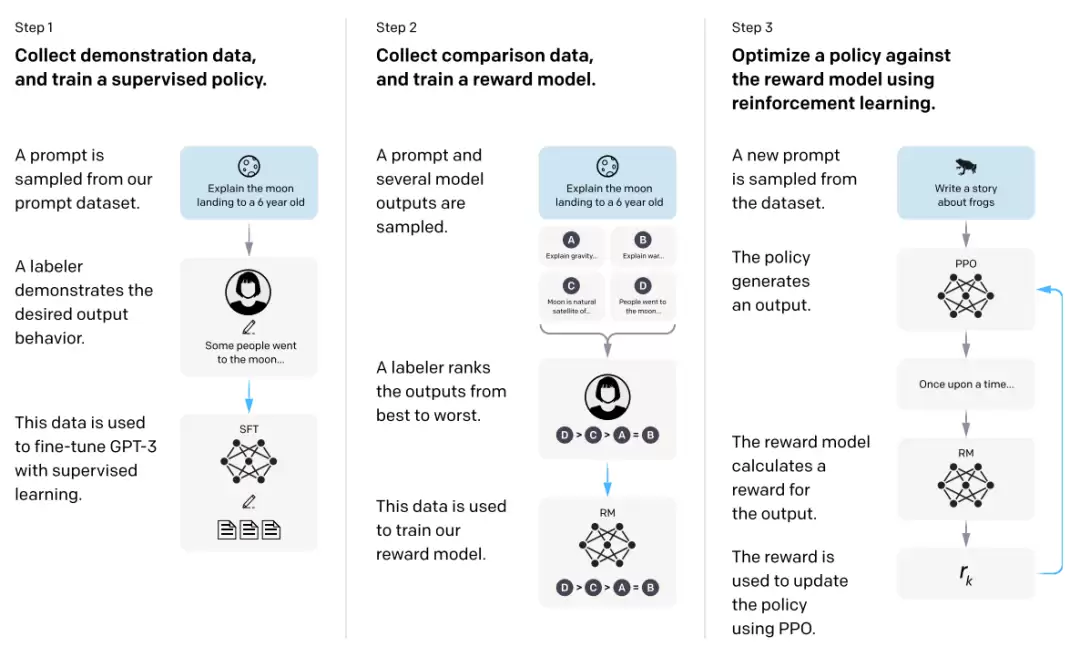
第一步,从prompt数据集中采样,标注员根据要求编写答案,形成描述性数据(Demonstration Data)。用这些数据微调GPT-3,得到监督学习模型(SFT)。
第二步,从prompt数据库采样,生成多个模型输出,由标注员打分或排序,形成比较性数据(Comparison Data),并用来训练奖励模型(RM)。奖励模型学会预测不同输出的偏好分数。
第三步,使用PPO算法优化奖励模型。从数据集中取样,模型根据初始化的SFT数据输出,奖励模型打分,PPO调整策略,让模型生成更符合人类期望的输出。
经过这三步,InstructGPT能生成高质量、高符合度的答案,最终演变为ChatGPT这样的对话模型。
结语
从零训练一个大语言模型,每一步都充满挑战和设计细节。预训练教会模型语言基础,指令微调引导它完成具体任务,奖励模型量化输出质量,RLHF则让人类反馈成为最终的优化信号。四个环节环环相扣,缺一不可。要想训练出高效、灵活且符合人类需求的模型,每个步骤都需要精心设计、反复实验——这也正是大模型训练的魅力所在。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:大模型训练全过程关键步骤与核心要点详解要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点格兰仕近期接连推出重大举措——布局芯片产业、建设工业4 0基地、启动对惠而浦的要约收购,这家厨电巨头如此密集地打出战略组合拳,放在以往几乎难以想象。9月28日,格兰仕在顺德总部高调宣布,明年年初即将实现AI芯片流片,合作伙伴赛科技同步发布了基于RISC-V开源架构的人工智能视觉处理平台,多家企业还联
近期,Cherry Studio 正式推送了 v1 0 0 版本更新,最大亮点是新增了联网搜索功能。如果你已经是这款工具的用户,想必已经收到了更新弹窗提醒。 联网搜索配置详解 启用新功能前,需要先进行相关配置。从界面设置来看,这次接入的搜索服务依赖的是第三方平台 ta vily。因此,你需要先注册账
神经形态计算作为第五代AI,通过模拟人脑神经网络实现高速并行处理与自主学习,功耗降低上千倍。英特尔Loihi、IBMTrueNorth等芯片在低功耗实时处理海量数据上取得突破,将颠覆机器学习和AI的未来发展。
人工智能的落地需大数据、算力和算法三大基础。机器学习和深度学习各有侧重,本地计算工作站因其灵活性和稳定性适用于前期开发。人工智能已广泛应用于扫码、电商、医疗等领域,算力是核心支撑。
- 日榜
- 周榜
- 月榜
热点快看