




DeepSeek新模型实测:小巧精悍,性能突破业界想象

就在刚刚,DeepSeek开源了一个3B模型DeepSeek-OCR。虽然体量不大,但模型思路创新的力度着实不小。众所周知,当前所有LLM处理长文本时都面临一个绕不开的困境:计算复杂度是平方级增长的
就在不久前,DeepSeek开源了一款3B规模的文档识别模型DeepSeek-OCR。虽然模型体积不大,但其设计思路的创新性却令人眼前一亮。
众所周知,目前所有大型语言模型处理长文本时都面临着一个棘手问题:计算复杂度呈平方级增长。文本序列越长,所需消耗的算力资源就越多。
面对这一挑战,DeepSeek团队提出了一个巧妙的解决方案。既然一张图像可以容纳大量文字信息,而且占用的Token数量更少,何不将文本直接转换为图像?这就是我们所说的“光学压缩”技术——通过视觉模态为文本信息“减负”。
而OCR技术恰好天然适合验证这个思路,因为它本身就是在完成“视觉→文本”的转换过程,而且其效果可以通过量化指标进行科学评估。
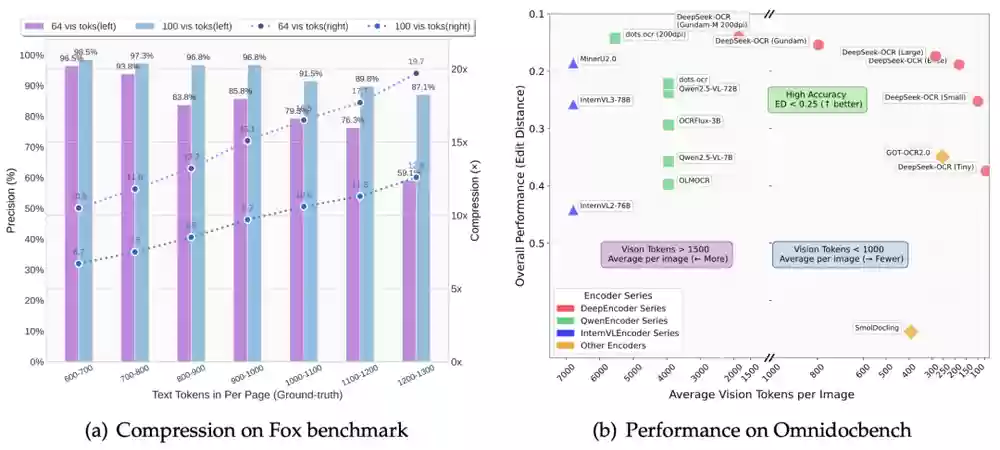
研究数据显示,DeepSeek-OCR的压缩率能够达到惊人的10倍,同时文字识别准确率仍保持在97%以上。
这意味着什么呢?简单来说,原本需要1000个文本Token才能表达的内容,现在仅需100个视觉Token就能完整呈现。即使将压缩率提升到20倍,模型的识别准确率依然维持在60%左右,整体效果相当出色。
在OmniDocBench基准测试中的表现尤为亮眼:
仅使用100个视觉Token,就超越了GOT-OCR2.0的表现;
用不到800个视觉Token,就大幅超越了MinerU2.0的性能。
更令人惊喜的是,在实际应用中,单张A100-40G显卡每天就能生成超过20万页的LLM/VLM训练数据。若扩展到20个计算节点,处理能力更是可以飙升至每天3300万页。
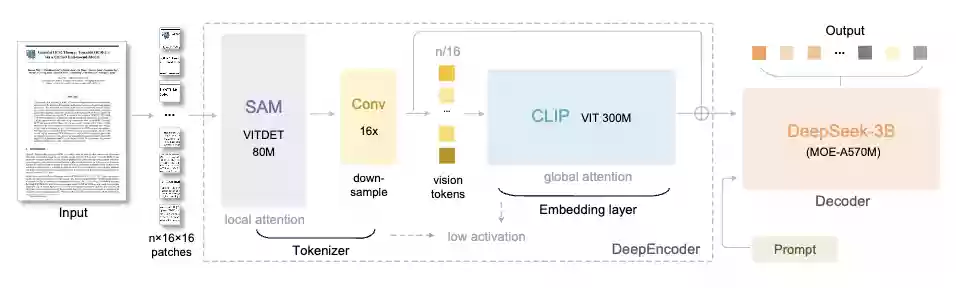
DeepSeek-OCR由两大核心组件构成:
DeepEncoder:负责图像特征提取和压缩处理;
DeepSeek3B-MoE:负责从压缩后的视觉Token中重建原始文本。
让我们重点解析DeepEncoder这部特征编码引擎的工作原理。
它的架构设计十分巧妙,通过将SAM-base和CLIP-large两个模型串联起来,前者专注于“局部注意力”提取视觉特征,后者负责“全局注意力”理解整体信息。
系统中间还加入了一个16倍压缩器,在进入全局注意力层之前大幅削减Token数量。
举例来说,一张1024×1024分辨率的图像,通常会被分割成4096个图像块Token。但经过压缩器处理后,进入全局注意力层的Token数量显著减少。
这样的设计优势在于,既保证了处理高分辨率输入的能力,又有效控制了激活内存的开销。
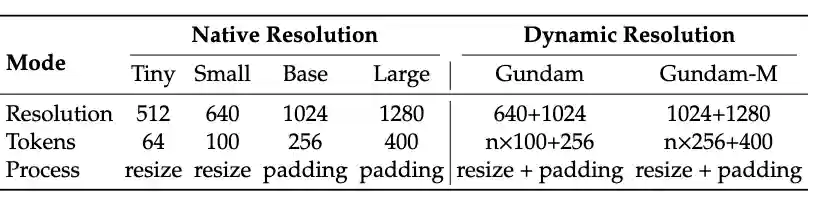
不仅如此,DeepEncoder还支持多分辨率输入,从512×512的Tiny模式到1280×1280的Large模式,一个模型就能胜任各种应用场景。
目前开源版本支持的模式包括原生分辨率的Tiny、Small、Base、Large四档,还有动态分辨率的Gundam模式,灵活性极高。
解码器采用的是DeepSeek-3B-MoE架构。
虽然模型总参数量只有3B,但采用了Mixture of Experts设计——64个专家中每次激活6个,再加上2个共享专家,实际激活参数量约为5.7亿。这让模型既具备了300亿参数模型的表达能力,又保持了5亿参数模型的推理效率。
解码器的任务是从压缩后的视觉Token中重建出原始文本,这个过程可以通过OCR风格的训练任务被紧凑型语言模型有效学习。
在数据准备方面,DeepSeek团队也是下足了功夫。
他们从互联网收集了3000万页的多语言PDF资料,涵盖约100种语言,其中中英文资料达2500万页。
数据分为两个类别:粗标注直接用fitz从PDF提取,主要训练少数语言的识别能力;精标注则使用PP-DocLayout、MinerU、GOT-OCR2.0等模型生成,包含检测与识别交织的高质量数据。
对于少数语言,团队还设计了“模型飞轮”机制——先用有跨语言泛化能力的版面分析模型做检测,再用fitz生成的数据训练GOT-OCR2.0,然后用训练好的模型反过来标注更多数据,如此循环往复最终生成了60万条样本。
此外还有300万条Word文档数据,主要用于提升公式识别和HTML表格解析能力。
在场景文字识别方面,团队从LAION和Wukong数据集收集图像,使用PaddleOCR进行标注,中英文各1000万条样本。
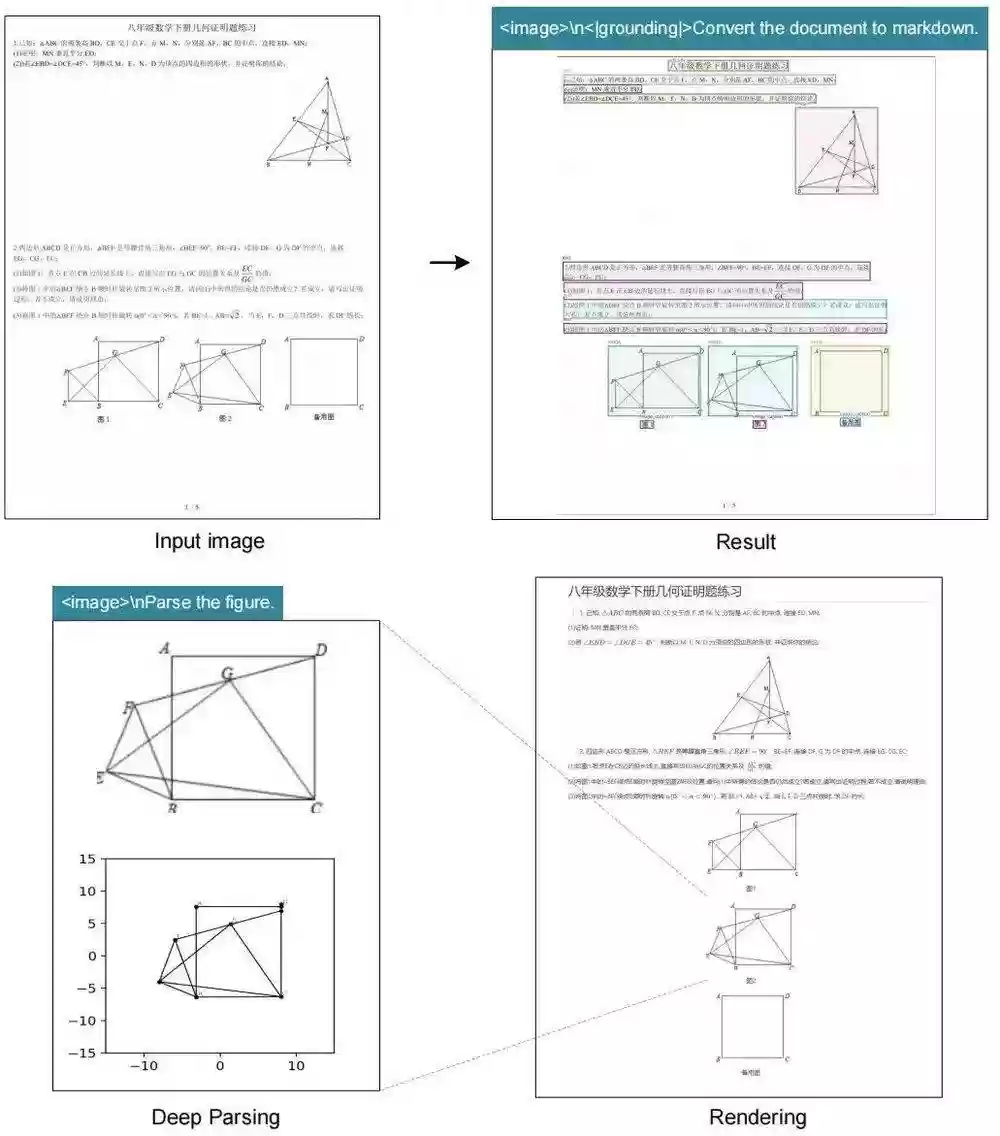
DeepSeek-OCR不仅能识别文字,还具备“深度解析”能力,只需一个统一的提示词,就能对各种复杂图像进行结构化提取:
图表:金融研究报告中的图表可以直接提取为结构化数据;
化学结构式:识别并转换为SMILES格式;
几何图形:对平面几何图形进行复制和结构化解析;
自然图像:生成密集描述文本。
这种能力在STEM领域的应用潜力巨大,尤其是化学、物理、数学等需要处理大量符号和图形的场景。

论文第一作者Haoran Wei此前曾供职于跳跃星辰,期间发布并开源了GOT-OCR2.0系统。
令人注意的是,DeepSeek团队在论文中还提出了一个有趣的构想——用光学压缩模拟人类的遗忘机制。
人类的记忆会随时间衰退,越久远的事情记得越模糊。DeepSeek团队设想,能不能让AI也具备类似的特性?于是,他们提出了这样的方案:
1. 把超过第k轮的历史对话内容渲染成图像;
2. 进行初步压缩,实现约10倍的Token数量削减;
3. 对于更久远的上下文,继续缩小图像尺寸;
4. 随着图像越来越小,内容也越来越模糊,最终达到“文本遗忘”的效果。
这确实很像人类记忆的衰退曲线:近期信息保持高保真度,久远记忆自然淡化。
虽然这仍是一个早期研究方向,但如果能够实现,对于处理超长上下文将是一个重大突破。

简而言之,DeepSeek-OCR表面上是个OCR模型,实际上是在探索一个更宏大的命题:能否用视觉模态作为LLM文本信息处理的高效压缩媒介?
初步答案是肯定的,7-20倍的Token压缩能力已经充分展现出来。
当然,团队也承认这只是一个开始。单纯的OCR还不足以完全验证“上下文光学压缩”,后续计划开展数字-光学文本交替预训练、“大海捞针”式测试,以及其他系统性评估。
不过无论如何,这在VLM和LLM的进化道路上,又开辟了一条全新的赛道。
回想去年这个时候,大家都在研究怎么让模型“记住更多”。今年DeepSeek却反其道而行之,不如让模型学会“忘记一些”。
确实,AI的进化有时候并不是做加法,而是做减法。小而精,也能玩出大花样,DeepSeek-OCR这个3B小模型就是最好的证明。
AI原生产品日报频道: 前沿科技
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Meta扎克伯格坦承AI智能体发展不及预期,超级智能仍需时间
IT之家 7 月 3 日消息,据《商业内幕》今天报道,Meta 首席执行官马克 · 扎克伯格在上周四的一场内部全员会中表示,公司仍在努力实现“超级智能”(Superintelligence),但目前还需要投入更多时间和精力。据两位参会人士透露,扎克伯格表示,Meta 正在向人工智能领域投入大量资源,

Agentic AI重构影像创作,影石Insta360联
全民影像记录时代到来,全景相机、运动相机、航拍无人机走进大众生活,每个人都能随手拍摄海量视频素材,但剪辑繁琐、高光筛选耗时、全景素材适配难等行业痛点始终未能彻底解决。市面上主流剪辑工具大多只聚焦后期编辑,平台适配流程复杂、模板同质化严重,针对360°全景画面的智能制作能力更是长期空白。与此同时,全球

微软Teams加强第三方AI智能体权限管理,需会议组织者确认后放行
IT之家 7 月 6 日消息,微软发文,宣布为 Microsoft Teams 会议应用推出全新的 AI 机器人管理策略,当第三方 AI 机器人尝试加入会议时,必须先获得会议组织者批准后才能进入。据介绍,目前微软已在 Teams 管理中心新增“Manage external bots and the

小猿AI接入多模态AI能力,推动智能学习体验升级
小猿AI升级为全学科AI学习助手,强化多模态能力,支持图像识别、文本理解与题目解析;拍照后可智能分析题型、匹配知识点并推荐练习;语文英语模块新增语句纠错、单词解释及作文辅助功能。小猿AI近期在产品能力上迎来重要升级,正式强化多模态AI能力,使其在图像识别、文本理解与题目解析方面表现更加全面。据产品体

阶跃AI推动多模态AI发展:语音与内容生成能力持续增强
阶跃AI正加速构建多模态AI能力,重点布局语音识别与生成、跨模态内容理解;强化语音交互,支持自然语音输入输出;提升图文理解能力,拓展至营销文案、知识整理等智能写作场景;向全面智能助手演进。阶跃AI正在加速推进多模态AI能力建设,重点布局语音识别、语音生成以及跨模态内容理解能力。在最新技术方向中,阶跃








- 热门数据榜



 相关攻略
相关攻略
 2026-07-13 14:42
2026-07-13 14:40
2026-07-13 14:36
2026-07-13 14:19
2026-07-13 14:16
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
热门教程
2026-07-13 14:42
2026-07-13 14:40
2026-07-13 14:36
2026-07-13 14:19
2026-07-13 14:16
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
