




美国AI领袖质疑谷歌选择:省钱却落后一年,英伟达成赢家?

AI短剧中上演的戏剧性情节,如今正在真实的科技行业里成为现实。 就在谷歌年度开发者大会(Google I O)如火如荼进行之际,AI领域的一位领军人物,却公开上演了一出“砸场子”的戏码。这背后,究竟隐藏着怎样的不满与行业变局? 几天前,正值谷歌I O大会期间,文生图领域的明星公司Midjourney

AI短剧中上演的戏剧性情节,如今正在真实的科技行业里成为现实。
就在谷歌年度开发者大会(Google I/O)如火如荼进行之际,AI领域的一位领军人物,却公开上演了一出“砸场子”的戏码。这背后,究竟隐藏着怎样的不满与行业变局?
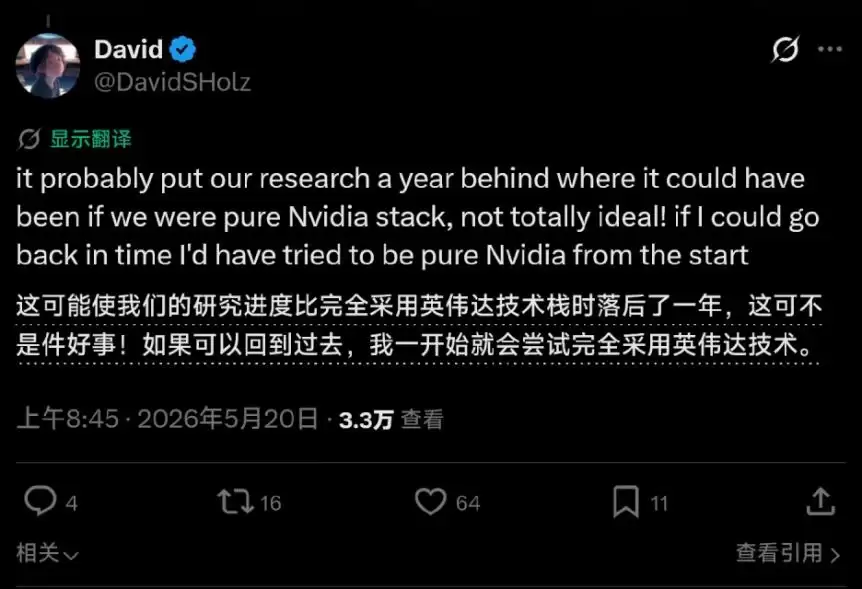
几天前,正值谷歌I/O大会期间,文生图领域的明星公司Midjourney的创始人兼CEO大卫·霍茨(David Holz)在社交平台X上公开吐槽谷歌TPU,瞬间引爆了硅谷AI圈的激烈讨论。他直言不讳地表示,由于早年选择谷歌TPU而非英伟达GPU作为核心训练设施,导致Midjourney的研究进度比原本可能达到的水平落后了整整一年。“如果能够重来,我会从一开始就完全采用英伟达芯片。”
这番言论之所以具有巨大杀伤力,是因为Midjourney曾是谷歌云推广自家AI芯片的一张“王牌”,双方有着深度合作,且Midjourney确实依靠TPU节省了可观的推理成本。此次公开“倒戈”,无异于为竞争对手英伟达做了一次极具说服力的背书。
那么,霍茨为何选择在这个关键时间点,如此不留情面地批评谷歌?
一次基于真实代价的公开复盘
霍茨的抱怨绝非一时兴起,而是一次基于真实商业代价的深度复盘。它精准地揭示了当前AI基础设施竞争最核心的矛盾:在硬件性能的比拼之外,软件生态的成熟度与易用性,才是决定研发效率与成败的真正关键。
要理解这份懊悔,首先需要厘清谷歌TPU和英伟达GPU在AI研究场景下的本质差异。
简单来说,英伟达GPU及其CUDA生态,好比是通用并行计算的“瑞士军刀”。CUDA平台自2007年开始布局,近二十年的生态沉淀,使其成为了AI研究领域的“通用语言”。研究员最常用的PyTorch框架与CUDA深度绑定,Hugging Face等平台上的开源模型权重默认以GPU格式发布,再加上Nsight性能分析器、NCCL通信库等一系列工具,共同构成了一套完整、成熟且被广泛接受的研究工具链。全球的AI研究员,几乎从学术生涯伊始,就在这个生态里学习和工作。
而谷歌TPU则是另一套体系。作为专用集成电路(ASIC),其底层架构围绕脉动阵列设计,专为深度学习张量运算优化,在大规模、稳定的训练任务上理论效率极高。但它主要要求使用JAX或TensorFlow框架,对PyTorch的长期原生支持并不完善。其社区资源、调试工具和问题排查经验相对匮乏,很多深度优化严重依赖谷歌自身的内部支持与文档。

回到Midjourney的具体需求——图像生成模型的研发,需要大量自定义算子实验、快速原型迭代,并随时调用Hugging Face等生态中的扩散模型组件。这些工作在GPU+PyTorch的环境下可谓得心应手,但在TPU上却可能步履维艰。例如,一个研究员想验证一个新想法,在成熟的GPU生态中或许只需几小时;而在TPU上,光是配置环境、适配框架和排查兼容性问题,就可能耗费数天。日积月累,便构成了霍茨口中那“被耽误的一年”研究时间。
当初为何选择谷歌TPU?
需要明确的是,霍茨的吐槽主要针对AI模型的研究和训练阶段。到了模型部署和推理阶段,商业逻辑就完全不同了。这也正是Midjourney当初迁移到谷歌TPU的核心动力:实打实地降低成本,并规避与科技巨头们争抢紧缺的英伟达高端显卡。
早在2024年,谷歌云就高调宣布,Midjourney已选择其作为核心基础设施供应商。具体策略是:利用谷歌的TPU v4/v5(基于JAX框架)来训练其第四代和第五代文生图大模型;同时,租用谷歌云上的英伟达GPU集群,来处理全球用户海量的日常图像生成请求。
这个选择非常现实。当时英伟达的H100等高端GPU一卡难求,Midjourney作为一家独立的AI创业公司,在采购议价和供应保障上根本无法与财大气粗的巨头竞争。而谷歌的TPU算力供应相对稳定,且对于图像生成这类大规模矩阵运算,纸面上的性价比(据称能节省约60%成本)极具诱惑力。
事实也证明了这一点。2025年第二季度,Midjourney将主力推理集群从英伟达A100/H100迁移到谷歌Cloud TPU v6e后,月度推理支出从约210万美元大幅降至70万美元以下,年化节省超过1680万美元,投资回本周期仅需11天。
换言之,TPU在规模化推理任务上的成本优势是真实存在的。霍茨真正懊恼的或许是:当初更优的策略应该是“研究阶段用英伟达生态快速打磨模型,待模型稳定后,再将推理任务迁移到谷歌TPU以降本增效”,而非从一开始就在TPU上开展所有研究,从而付出了高昂的时间机会成本。
英伟达的真正护城河是生态
霍茨的公开吐槽,本质上是一份关于英伟达生态护城河的强力“证词”。这条护城河的关键,不在于单一芯片的绝对算力,而在于无数研究员形成的工作习惯、数以万计的开源代码库与工具,以及整个学术界默认GPU作为实验平台的强大行业惯性。
数据显示,直到2026年,PyTorch在顶级AI研究论文中的使用占有率仍高达85%。几乎所有前沿研究的开源代码都默认基于英伟达硬件编写。这意味着,任何选择TPU进行前沿研究的团队,都必须承担一个巨大的隐性成本:将自己与主流开发者社区相对隔离,放弃大量现成的工具和解决方案,在一个相对小众的技术栈中独自摸索。
这就是为什么即便TPU在某些基准测试指标上已与GPU相当甚至更优,大多数研究实验室和初创公司仍然默认选择英伟达。硬件性能或许可以通过巨额投入快速追赶,但生态的积累、习惯的养成无法速成。黄仁勋花了近二十年时间构建的这条软件与生态护城河,正是英伟达最核心、最难以复制的资产。
谷歌显然深刻意识到了这一问题。在今年的谷歌云Next大会上,谷歌发布了第八代TPU,并首次采用双芯片策略:TPU 8t(专用于训练)和TPU 8i(专用于推理)。这是TPU历史上第一次将训练和推理分拆成架构完全不同的专用芯片,目的正是为了解决霍茨所吐槽的“一颗芯片难以兼顾所有场景”的痛点。
TPU 8t代号Sunfish,由博通合作设计,面向大规模模型预训练。超级Pod规模达9600颗芯片,训练性价比据称比上代提升2.7倍。TPU 8i代号Zebrafish,由联发科设计,专攻推理场景,在大型MoE模型低延迟推理上性价比提升80%。两款芯片均采用台积电2纳米工艺,预计2027年量产。

谷歌的双芯片战略本身,就是一次重要的战略承认:训练和推理已经分化成两种截然不同的工作负载,需要不同的架构进行专门优化。这与英伟达“一块GPU通吃训练与推理”的通用路线形成鲜明对比,也是对亚马逊Trainium3等专用推理芯片的正面回应。
不仅如此,针对霍茨对TPU生态兼容性的抱怨,谷歌同步推出了TorchTPU项目——一个旨在让PyTorch能原生、高效运行在TPU上的重大工程计划,目前处于预览状态。按照路线图,TorchTPU将支持PyTorch的动态图模式(Eager Mode),并与vLLM等热门推理工具深度集成。如果该项目最终成熟,坚守PyTorch生态的研究团队将首次能够在不重写大量代码的前提下,无缝使用TPU的强大算力。
然而,TorchTPU目前仍是预览版。像霍茨所期望的那种“轻松修改模型架构、调整自定义算子、快速验证新想法”的流畅研究体验,在未来的TPU 8t上能否真正实现,还需要大量实战检验。一扇通往更开放生态的大门已经打开,但门后的道路是否平坦宽阔,恐怕要等到2027年芯片正式量产后才能见分晓。
Claude为何能横跨三大算力平台?
既然Midjourney对TPU的训练生态有诸多不满,那么,作为行业新领头羊的Anthropic,是如何解决同时驾驭三大算力平台的挑战的呢?要知道,他们同时在英伟达GPU、谷歌TPU和亚马逊Trainium三套不同的硬件上训练和运行其Claude大模型。
这背后有着深刻的商业与战略逻辑。Anthropic最初是AI第一集团的追赶者,财力远不及谷歌和OpenAI。因此,他们接受了谷歌和亚马逊的巨额战略投资,而使用这两家巨头的自研芯片,便是重要的交换条件之一。
谷歌和亚马逊都是Anthropic的战略投资者,两家巨头先后承诺投资近100亿美元,加上微软的50亿美元,相当于全球三大云计算巨头在合力支持Anthropic。这些投资有很大一部分转化为了谷歌云和AWS的云服务营收,因为Anthropia目前使用着超过百万颗亚马逊Trainium芯片和数十万颗谷歌TPU,并计划未来拓展到百万TPU阵列的规模。
与此同时,谷歌云、AWS和微软Azure也是Claude模型在全球企业级(B端)市场的主要分发平台。三大云巨头都想用自己的销售网络帮助推广Claude,既获得营收分成,更关键的是把宝贵的AI算力流量留在自家的云服务器内。这种被多方鼎力支持的全面通吃局面,让Anthropic迅速成长为硅谷历史上底牌最足的独立AI巨头之一。最近,他们甚至与SpaceX达成了算力租赁协议,每年支付150亿美元使用其超算中心的英伟达GPU。
那么,Anthropic究竟是如何在工程上实现同时驾驭三大平台芯片的呢?
根据其最新披露的策略,核心是“为不同工作负载匹配最适合的芯片架构”:英伟达GPU承接前沿研究实验和快速原型开发;谷歌TPU和亚马逊Trainium则分别承接超大规模模型训练和高并发推理的主力工作负载。这种安排不仅是为了追求极致性能与性价比,更是在两家超级计算供应商之间形成制衡,防止被单一平台锁定从而丧失定价权。
Anthropic与亚马逊的合作规模尤为惊人。双方已签署长期协议,Anthropic将在未来十年向AWS投入超过1000亿美元,以获得海量且稳定的算力容量保障。有趣的是,在谷歌云Next大会宣布与Anthropic深化合作时,亚马逊立刻站出来“邀功”,声称Claude最新模型的训练完全在自家的Trainium芯片上完成。

Anthropic靠什么实现“脚踩三条船”?
Anthropic能够走出这条独特的技术路线,有一个关键的技术基因:其核心创始团队来自Google Brain,JAX框架是他们的“母语”。从一开始,Anthropic就将JAX作为核心训练框架——JAX的设计哲学是硬件无关,同一套代码可以通过其XLA编译器,在GPU、TPU乃至Trainium等不同硬件后端上运行。
这与Midjourney的路径恰好相反。Midjourney是先在建好的PyTorch+GPU生态中工作,再试图迁移到TPU,因此承受了高昂的生态迁移和适配成本。而Anthropic则是从起点就选择了硬件无关的编程范式,为多平台战略打下了基础。
当然,这种多平台策略的工程代价同样高昂。Anthropic每次模型更新都要在三套不同的硬件架构上分别进行测试和优化,每一个出现的Bug都可能有三个潜在的成因,部署复杂度是单一平台的三倍以上。这是他们为获得供应链安全和议价能力所必须支付的“工程账单”。
具体来说,谷歌TPU体系基于JAX和XLA编译器,而亚马逊Trainium体系则基于AWS自研的Neuron SDK。这意味着Anthropic的核心训练代码不能直接平移。其工程团队必须与谷歌和亚马逊的芯片团队深度合作,将复杂的模型算子用三套不同的硬件底层逻辑进行重写和极致优化。这种人力与时间成本,远超纯粹依赖英伟达单一生态的OpenAI。
相比之下,Midjourney团队规模较小,难以支撑如此庞大的底层跨平台优化工程。面对TPU相对小众的JAX/XLA环境时,一旦遇到棘手的硬件级Bug或兼容性问题,整个团队的研发进度就可能陷入停滞。
多平台的风险也曾真实显现。2025年8月至9月,部分Claude用户曾报告模型性能下降。Anthropic事后复盘披露了三个独立的基础设施漏洞,分别涉及网络路由错误、服务器配置错误和编译器漏洞,这些问题正源于其复杂的多平台混合架构。
为此,Anthropic在其研究论文中反复强调一个核心工程原则:保持模型架构的极度简单与高度的可组合性。模型层设计得越纯粹、越少使用复杂的“技巧”,在面对多芯片平台交叉测试时,底层暴露出的硬件特异性Bug就越少,从而用“设计上的克制”来化解“平台上的繁复”。
在付出了这笔高昂的工程账单后,Anthropic收获了令人羡慕的战略果实。根据最新的总拥有成本(TCO)分析,谷歌TPU和亚马逊Trainium在大规模模型推理时的性价比,比同等规模的英伟达平台高出50%以上。如果说OpenAI赌的是“英伟达纯血生态+单点超大算力”的垂直整合路线,那么Anthropic则是用三倍的工程复杂度,将自己打造成了一个强大的“跨平台算力黏合体”。这种底层基础设施的全面打通,让Claude在商业落地竞争中,拥有了成本更低、且不受任何单一供应商掣肘的弹性算力后方。
未来格局:专用芯片时代的竞争逻辑
回过头看,霍茨的那条推文,某种程度上是AI基础设施竞争进入深水区的一个缩影。未来几年的市场格局,已经逐渐清晰。
训练侧:英伟达GPU仍是研究实验和快速迭代的首选平台,其生态优势无可替代。但在超大规模、架构稳定的模型预训练上,谷歌TPU和亚马逊Trainium正凭借显著的性价比优势侵蚀市场份额。谷歌TPU 8t和亚马逊Trainium3的持续进化,意味着顶级AI实验室将越来越倾向于“研究用GPU,大规模训练用专用芯片”的混合策略。
推理侧:市场格局对挑战者更为有利。推理已是AI算力支出中增长最快的部分,2026年初占比达55%,预计2030年将升至75%。在这个场景下,TPU和Trainium的专用架构优化能带来如Midjourney案例中高达65%的成本削减,经济账非常清晰。谷歌TPU 8i正是针对这一趋势的定向武器。
生态侧:战局更为长期和关键。TorchTPU项目能否真正让PyTorch研究员实现无缝迁移,是谷歌在2027年面临的关键挑战。亚马逊的策略则更为务实,始终将Trainium与PyTorch的深度兼容性作为主打卖点,通过Bedrock平台上的大量企业客户,悄然构建自己的应用层生态。
当然,英伟达绝不会坐视不理。CUDA生态的持续进化与Blackwell等新架构的推出,便是对“GPU不是AI研究唯一选择”论调的最直接反击。
供给侧的变量同样值得关注。谷歌TPU的大规模量产受制于台积电先进封装产能,原定2026年达到400万颗的目标已推迟至2027年。这意味着即便市场需求旺盛,TPU的供给在2026年仍将是制约因素,反而给英伟达留下了关键的缓冲空间。
对于大多数中小型AI公司而言,霍茨的懊恼依然具有现实的参考意义:在研究探索阶段全用英伟达生态,摩擦成本最小,迭代速度最快。等到模型架构稳定、推理规模上来后,再综合评估迁移到TPU等专用芯片的经济账。这并非因为英伟达绝对更好,而是因为在公司规模较小时,生态的便利性和研发效率成本,会压倒硬件本身的采购成本。
而对于Anthropic这个量级的顶尖实验室,三平台策略的逻辑则截然不同:它不只为了省钱,更是为了确保供应链安全与弹性,并在与亚马逊、谷歌等巨头的长期合作中保持强大的议价能力。
硬件峰值性能 vs 开发生态效率,采购性价比 vs 研究迭代速度,专用优化 vs 通用灵活——这正是当前AI芯片战争最核心的几组矛盾。谷歌用双TPU战略试图两端兼顾,亚马逊用兼容性策略绕过生态壁垒,英伟达则用二十年积累的软件护城河抵御所有挑战者。
在这个复杂多维的竞争棋盘上,没有玩家能买下所有筹码,也没有哪家公司的选择是绝对错误的,无非是在性能、成本、效率、安全之间做出权衡,并付出相应的代价。显然,AI芯片战争的计分方式,早已超越了单纯的性能指标。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

王坚九问九答:中美AI从泳池到同一片大海
2026智源大会上,王坚与黄铁军展开对话。王坚认为应超越“AI”框架,在动物、人类与机器智能的更大框架下思考,坚信AI不会替代人类,并指出如今中美面对的是同一片大海。黄铁军建议从业者要有自己的想法,并在该下决心时果断决策。

拓普集团同心圆模式如何突破效率墙发展瓶颈
拓普集团2016年不及中鼎股份,2025年全面反超;但2026年营收创新高利润首降,毛利率跌破行业均值。机器人30万套产能年收入仅1359万元,一季度毛利率续降至19 26%。

比亚迪闪充技术布局加拿大市场充电桩先行
比亚迪在加拿大未正式售车,但已启动闪充网络布局,招聘闪充业务发展经理,负责成本模型、合作伙伴及电网升级。全球规划中,欧洲为重点市场,加拿大政策对中国车企持开放态度。

极狐贝塔T1纯电小车6万级焕新,官方暗示玩大的
极狐T1焕新升级为贝塔T1,将于6月16日上市。尾部改为贯穿式尾灯,配大尺寸运动尾翼,运动感增强。官方暗示空间或电池可能升级。现款售价6 28-8 78万元,提供320km和425km续航,轴距2770mm,空间越级,配置丰富,上市首月订单超3 5万台。

三星Galaxy Z Fold8 Ultra等三款折叠屏手机机模曝光
科技博主曝光三星三款折叠新机模型,包括ZFlip8、ZFold8及ZFold8Ultra。ZFlip8与Fold8Ultra延续前代设计,边框有望收窄。标准版ZFold8首次采用宽折叠方案,外屏更短但宽度翻倍,展开后获得7 6英寸接近4:3比例的屏幕,提升多任务与视频观看体验。目前展示的仍为早期模型。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-19 22:05
2026-07-19 21:53
2026-07-19 21:52
2026-07-19 21:52
2026-07-19 21:52
2026-07-19 21:52
2026-07-19 21:43
2026-07-19 21:42
热门教程
2026-07-19 22:05
2026-07-19 21:53
2026-07-19 21:52
2026-07-19 21:52
2026-07-19 21:52
2026-07-19 21:52
2026-07-19 21:43
2026-07-19 21:42
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















